Latent Component Gaussian Process (LCGP): replicated 1D illustration#
The experiment compares LCGP behavior under three replication designs and two training modes:
Axis |
Options |
|---|---|
Replication design |
uniform, skewed, hotspot |
Training mode |
replicated-data reduction ( |
Figure type |
output predictions ( |
The notebook is deterministic: each (case, submethod) run receives its own fixed random seed.
Execution requirements#
This page expects the following packages to already be available in the JupyterBook build environment or to be installed during runtime:
lcgp
pandas
matplotlib
tensorflow-probability[tf]
pytest
Imports and global configuration#
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1783219055.144210 672 cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1783219056.715761 672 cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
# All options executed by this JupyterBook page.
CASES = (1, 2, 3)
SUBMETHODS = ("rep", "full")
PLOT_MODES = ("y", "g")
BASE_SEED = 42
RESULTS_ROOT = Path("results_figure_jupyterbook")
RESULTS_ROOT.mkdir(parents=True, exist_ok=True)
CASE_LABELS = {
1: "Uniform replication",
2: "Uneven replication",
3: "Hotspot replication at selected x",
}
True function#
The input is one-dimensional, $x \in [0,1]$, while the response has three output dimensions:
$$y(x) = \begin{bmatrix} f_1(x) \ f_2(x) \ f_3(x) \end{bmatrix}.$$
The three outputs share the same scalar input but have different shapes. This gives a compact multi-output regression problem where replication can affect both mean estimation and uncertainty quantification.
Replicated data generators#
Comparing multiple scenarios of replications#
summary_rows: list[dict] = []
metric_rows: list[dict] = []
diagnostic_rows: list[dict] = []
for case in CASES:
for submethod in SUBMETHODS:
seed = BASE_SEED + 100 * case + (0 if submethod == "rep" else 1)
xtrain, ytrain, xtest, ytrue = build_dataset(case, seed=seed)
rep_summary = summarize_replication(case, submethod, xtrain, seed)
summary_rows.append({
"case": rep_summary.case,
"case label": CASE_LABELS[case],
"submethod": rep_summary.submethod,
"N total": rep_summary.n_total,
"unique x": rep_summary.n_unique,
"rep min": rep_summary.rep_min,
"rep mean": rep_summary.rep_mean,
"rep max": rep_summary.rep_max,
"seed": rep_summary.seed,
})
display(Markdown(f"### Case {case}: {CASE_LABELS[case]} — `{submethod}`"))
summary_rows_df = pd.DataFrame([summary_rows[-1]])
display_table(summary_rows_df)
modelrun, predmean, ypredvar, yconfvar, elapsed = fit_lcgp(
xtrain=xtrain,
ytrain=ytrain,
xtest=xtest,
ytrue=ytrue,
submethod=submethod,
runno=f"case_{case}_{submethod}",
)
metrics = evaluate_prediction(ytrue, predmean, yconfvar)
metric_rows.append({
"case": case,
"case label": CASE_LABELS[case],
"submethod": submethod,
"training time (s)": elapsed,
**metrics,
})
metric_rows_df = pd.DataFrame([metric_rows[-1]])
display_table(metric_rows_df)
mdl = modelrun.model
lLmb, lLmb0, lsigma2s, lnugGPs = mdl.get_param()
if mdl.submethod == 'rep':
r = np.asarray(mdl.r.numpy())
elif mdl.submethod == 'full':
r = np.array([1.])
diagnostic_rows.append({
"case": case,
"case label": CASE_LABELS[case],
"submethod": submethod,
# "diag_D": np.asarray(mdl.diag_D.numpy()).round(2).tolist(),
# "phi^T phi diag": np.diag(mdl.phi.numpy().T @ mdl.phi.numpy()).round(2).tolist(),
"lengthscales": [np.asarray(lLmb[k].numpy()).round(2).tolist() for k in range(lLmb.shape[0])],
"noise std fitted": np.sqrt(np.exp(lsigma2s.numpy())).round(2).tolist(),
# "rep avg/min/max": f"{np.mean(r):.1f} / {np.min(r)} / {np.max(r)}",
})
diagnostic_rows_df = pd.DataFrame([diagnostic_rows[-1]])
display_table(diagnostic_rows_df)
run_dir = RESULTS_ROOT / f"case_{case}_{submethod}"
run_dir.mkdir(parents=True, exist_ok=True)
fig_y = plot_output_predictions(
case=case,
submethod=submethod,
xtrain=xtrain,
ytrain=ytrain,
xtest=xtest,
ytrue=ytrue,
predmean=predmean,
yconfvar=yconfvar,
outfile=run_dir / "lcgp_output.png",
)
plt.show()
fig_g = plot_latent_gps(
case=case,
submethod=submethod,
modelrun=modelrun,
xtest=xtest,
outfile=run_dir / "lcgp_latent.png",
)
plt.show()
display(Markdown(f"Saved figures to `{run_dir.as_posix()}/`."))
Case 1: Uniform replication — rep
| case | case label | submethod | N total | unique x | rep min | rep mean | rep max | seed |
|---|---|---|---|---|---|---|---|---|
| 1 | Uniform replication | rep | 41 | 16 | 1 | 2.56 | 5 | 142 |
======= VARIANCE OF G ======
tf.Tensor([0.99256334 0.99888453 0.93669309], shape=(3,), dtype=float64)
| case | case label | submethod | training time (s) | RMSE | NRMSE | 95% PI coverage | 95% PI width | DSS |
|---|---|---|---|---|---|---|---|---|
| 1 | Uniform replication | rep | 5.19 | 0.04 | 0.07 | 1 | 0.23 | -15.61 |
| case | case label | submethod | lengthscales | noise std fitted |
|---|---|---|---|---|
| 1 | Uniform replication | rep | [[0.13], [0.21], [0.09]] | [0, 0.01, 0] |
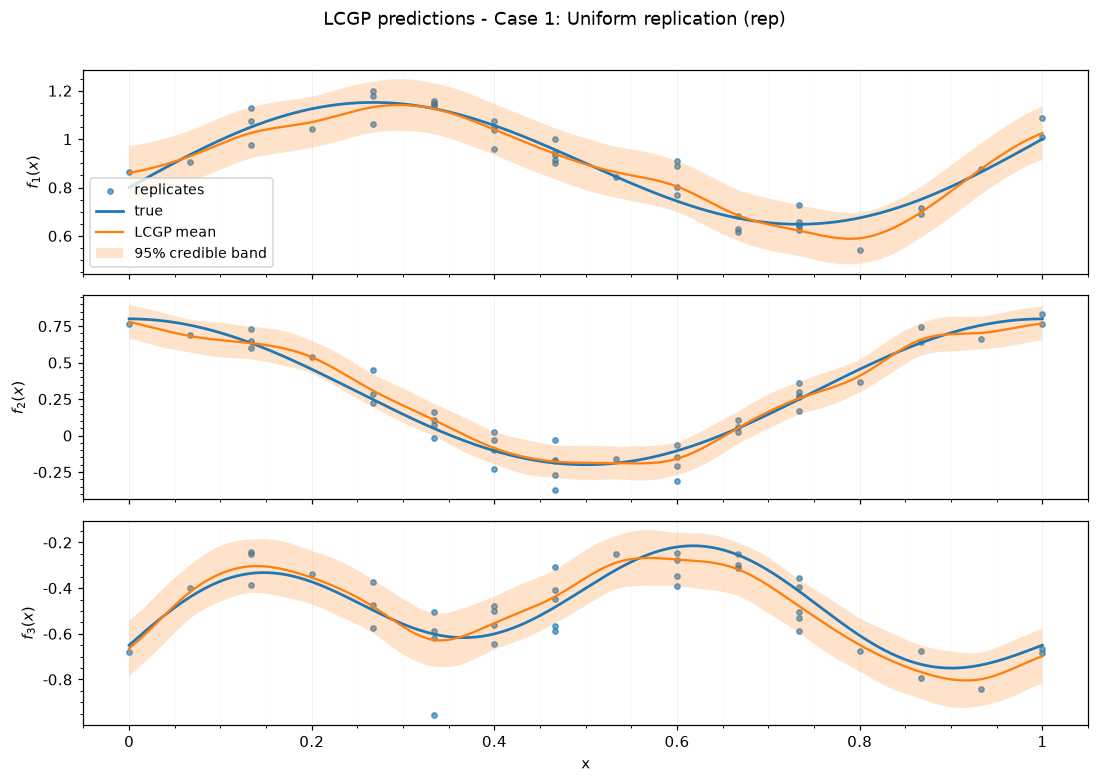
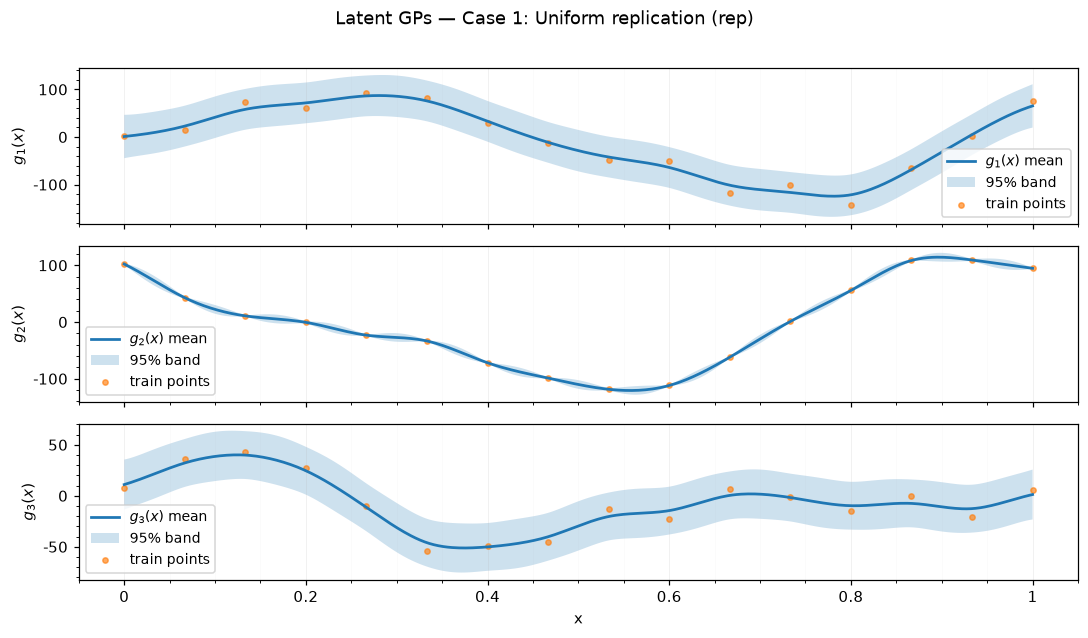
Saved figures to results_figure_jupyterbook/case_1_rep/.
Case 1: Uniform replication — full
| case | case label | submethod | N total | unique x | rep min | rep mean | rep max | seed |
|---|---|---|---|---|---|---|---|---|
| 1 | Uniform replication | full | 51 | 16 | 1 | 3.19 | 5 | 143 |
======= VARIANCE OF G ======
tf.Tensor([0.97259295 0.96453525 0.99985276], shape=(3,), dtype=float64)
| case | case label | submethod | training time (s) | RMSE | NRMSE | 95% PI coverage | 95% PI width | DSS |
|---|---|---|---|---|---|---|---|---|
| 1 | Uniform replication | full | 3.01 | 0.03 | 0.06 | 0.97 | 0.18 | -16.95 |
| case | case label | submethod | lengthscales | noise std fitted |
|---|---|---|---|---|
| 1 | Uniform replication | full | [[0.18], [0.21], [0.18]] | [0.27, 0.22, 0.82] |
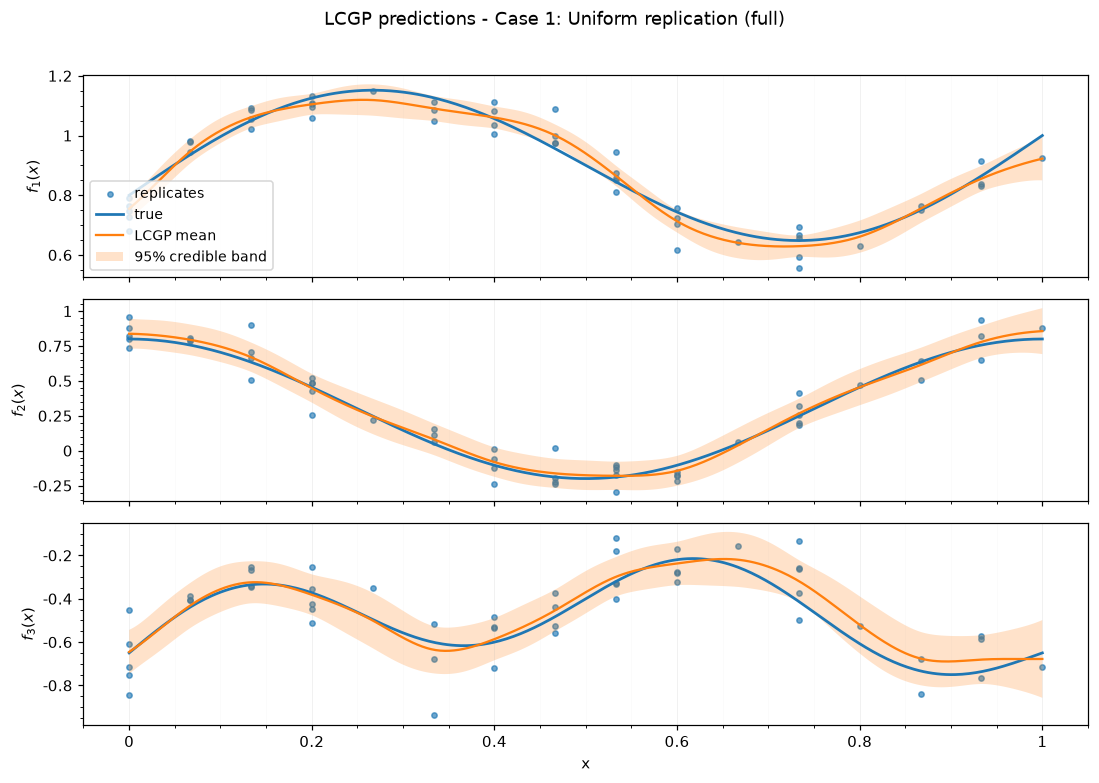
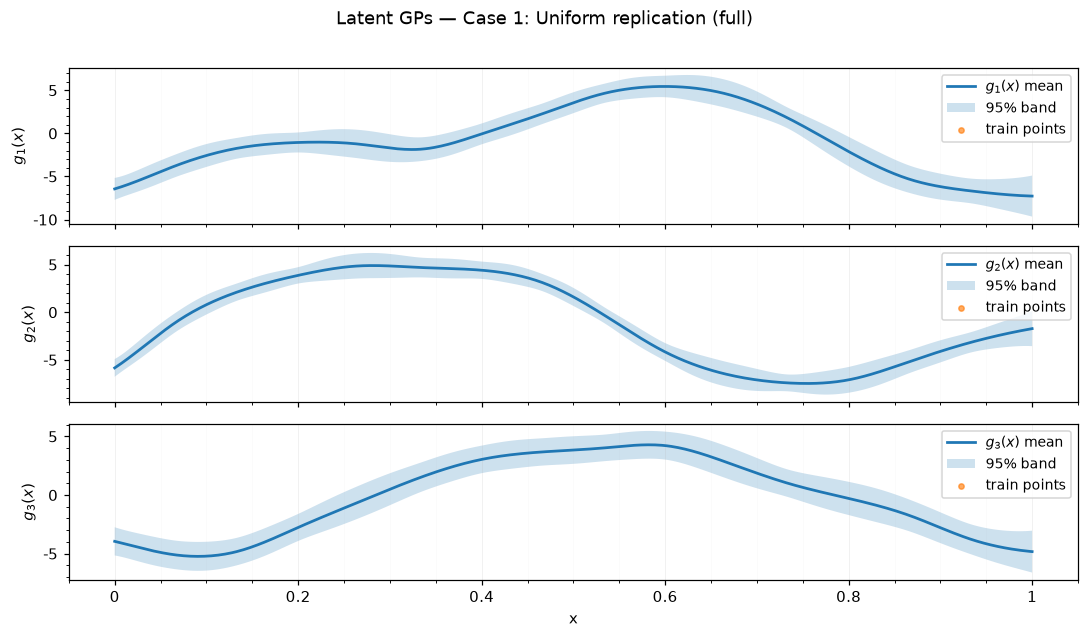
Saved figures to results_figure_jupyterbook/case_1_full/.
Case 2: Uneven replication — rep
| case | case label | submethod | N total | unique x | rep min | rep mean | rep max | seed |
|---|---|---|---|---|---|---|---|---|
| 2 | Uneven replication | rep | 199 | 40 | 1 | 4.97 | 20 | 242 |
======= VARIANCE OF G ======
tf.Tensor([0.99999088 0.99905397 0.95536713], shape=(3,), dtype=float64)
| case | case label | submethod | training time (s) | RMSE | NRMSE | 95% PI coverage | 95% PI width | DSS |
|---|---|---|---|---|---|---|---|---|
| 2 | Uneven replication | rep | 2.67 | 0.03 | 0.05 | 0.96 | 0.09 | -19.76 |
| case | case label | submethod | lengthscales | noise std fitted |
|---|---|---|---|---|
| 2 | Uneven replication | rep | [[0.19], [0.28], [0.25]] | [0.04, 0.07, 0.09] |
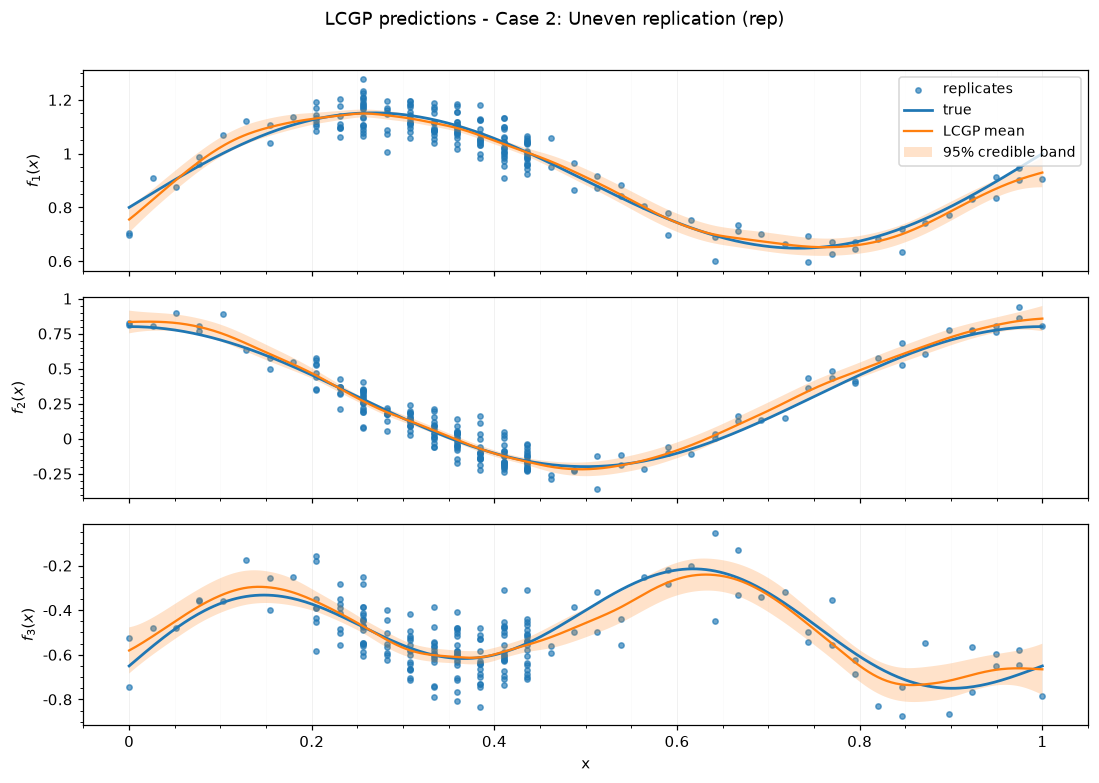
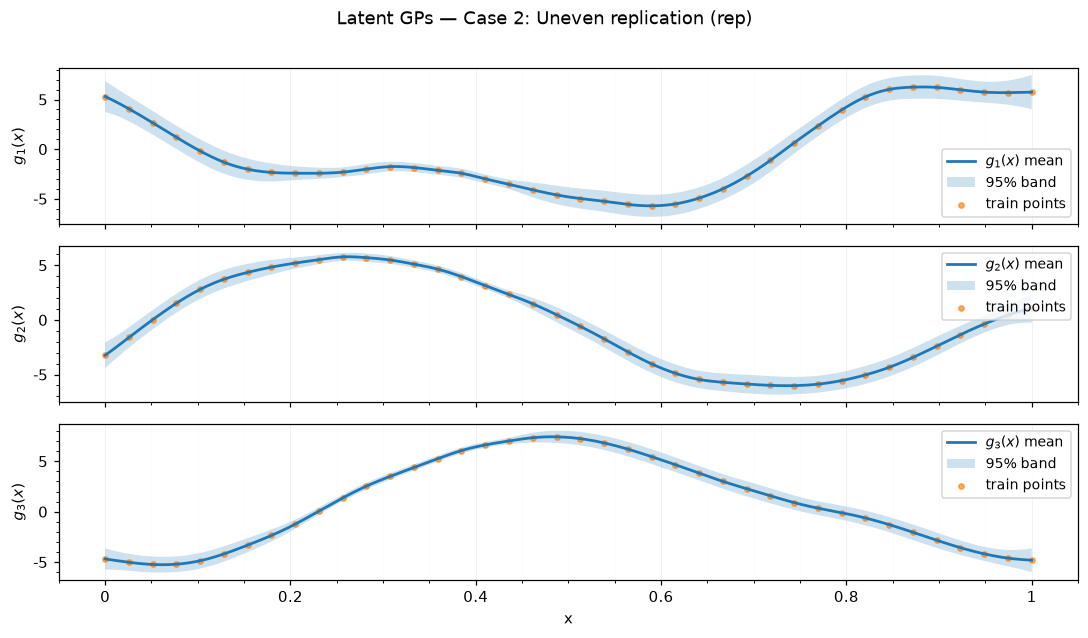
Saved figures to results_figure_jupyterbook/case_2_rep/.
Case 2: Uneven replication — full
| case | case label | submethod | N total | unique x | rep min | rep mean | rep max | seed |
|---|---|---|---|---|---|---|---|---|
| 2 | Uneven replication | full | 198 | 40 | 1 | 4.95 | 20 | 243 |
======= VARIANCE OF G ======
tf.Tensor([0.92479125 0.99611432 0.98610819], shape=(3,), dtype=float64)
| case | case label | submethod | training time (s) | RMSE | NRMSE | 95% PI coverage | 95% PI width | DSS |
|---|---|---|---|---|---|---|---|---|
| 2 | Uneven replication | full | 9.46 | 0.02 | 0.04 | 1 | 0.15 | -18.87 |
| case | case label | submethod | lengthscales | noise std fitted |
|---|---|---|---|---|
| 2 | Uneven replication | full | [[0.27], [0.13], [0.38]] | [0.73, 0.31, 0.96] |
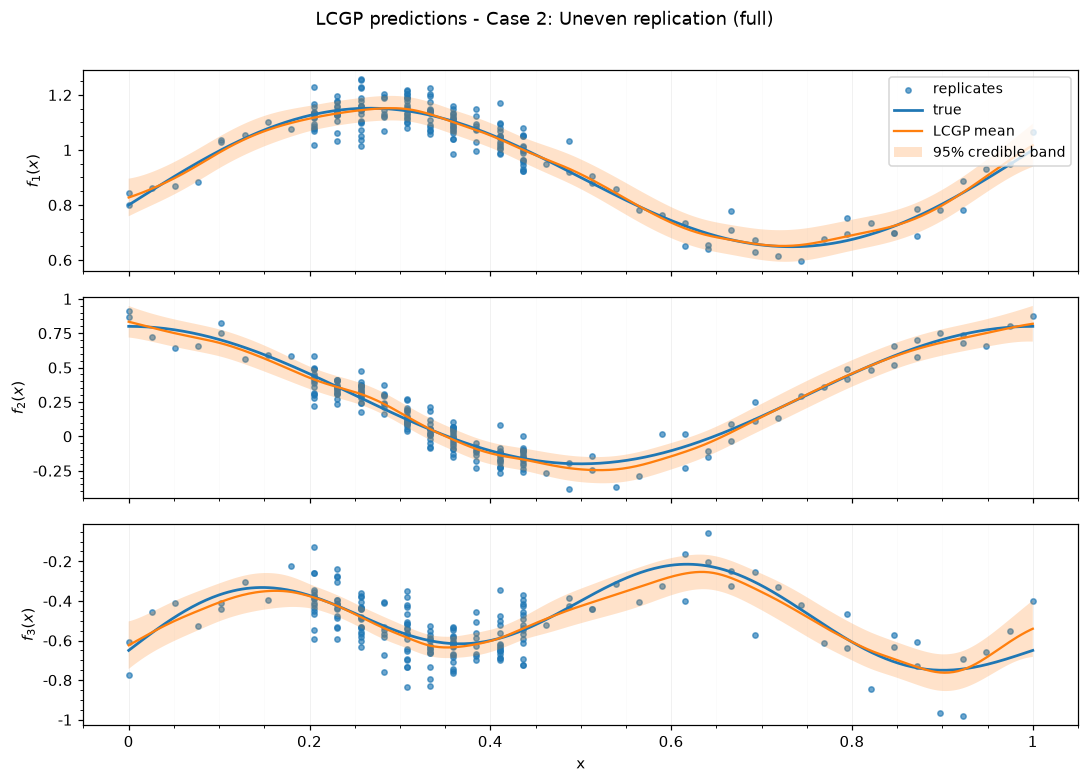
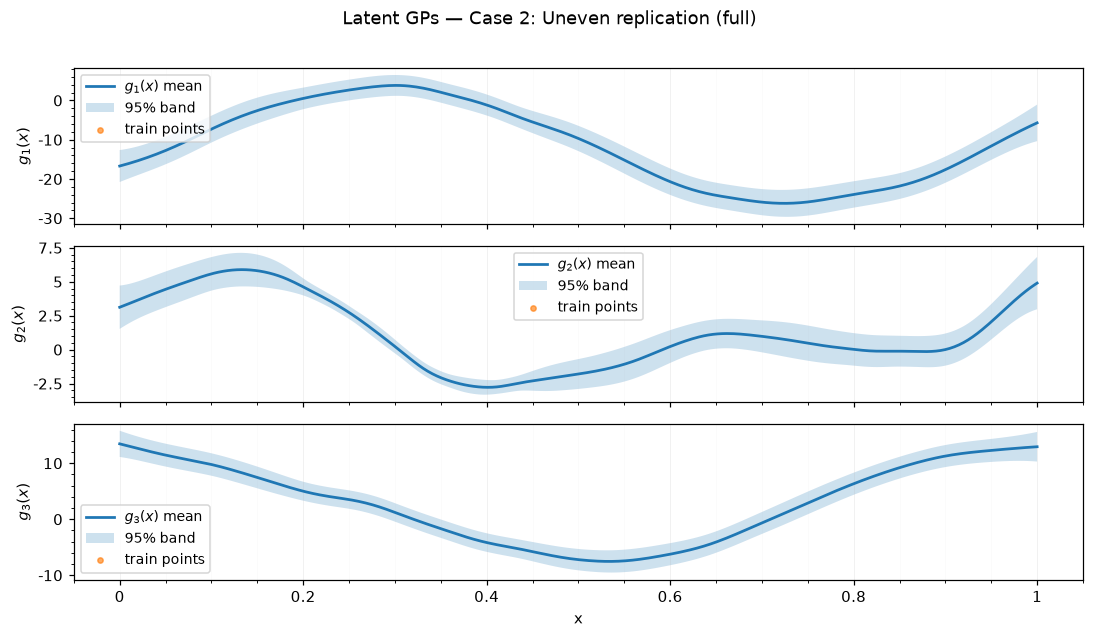
Saved figures to results_figure_jupyterbook/case_2_full/.
Case 3: Hotspot replication at selected x — rep
| case | case label | submethod | N total | unique x | rep min | rep mean | rep max | seed |
|---|---|---|---|---|---|---|---|---|
| 3 | Hotspot replication at selected x | rep | 96 | 50 | 1 | 1.92 | 21 | 342 |
======= VARIANCE OF G ======
tf.Tensor([0.98413068 0.99982956 0.94817331], shape=(3,), dtype=float64)
| case | case label | submethod | training time (s) | RMSE | NRMSE | 95% PI coverage | 95% PI width | DSS |
|---|---|---|---|---|---|---|---|---|
| 3 | Hotspot replication at selected x | rep | 2.19 | 0.03 | 0.05 | 0.97 | 0.12 | -18.99 |
| case | case label | submethod | lengthscales | noise std fitted |
|---|---|---|---|---|
| 3 | Hotspot replication at selected x | rep | [[0.18], [0.19], [0.25]] | [0.05, 0.08, 0.11] |
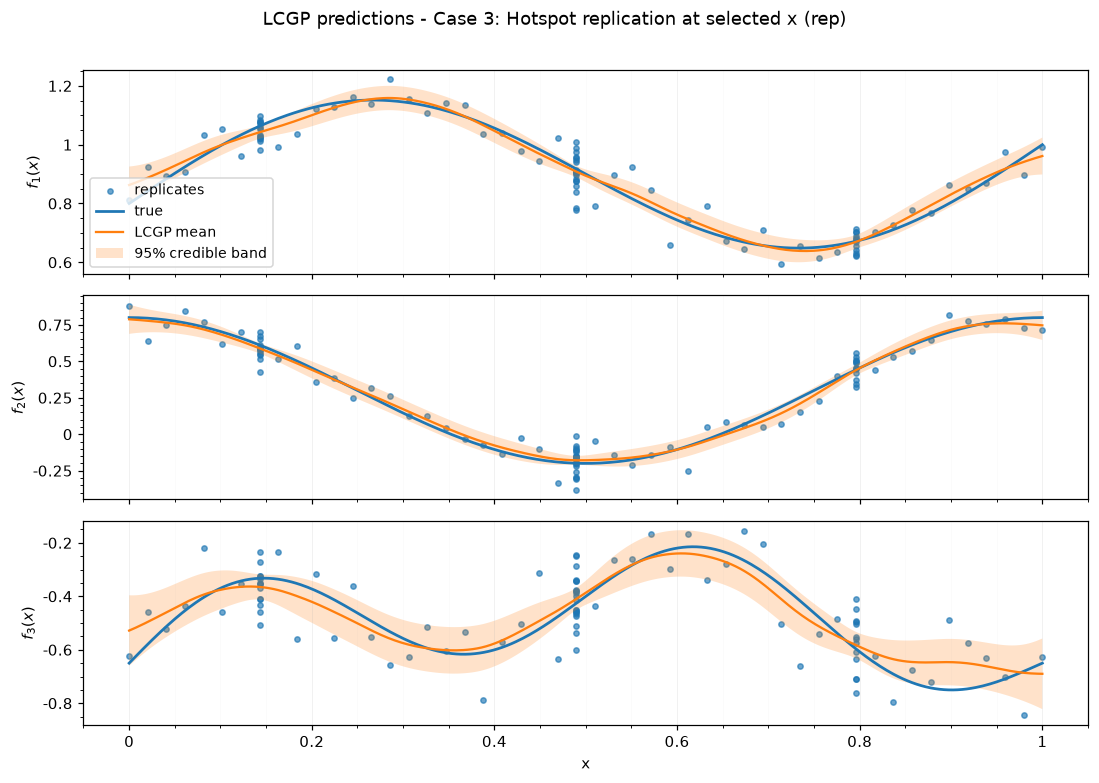
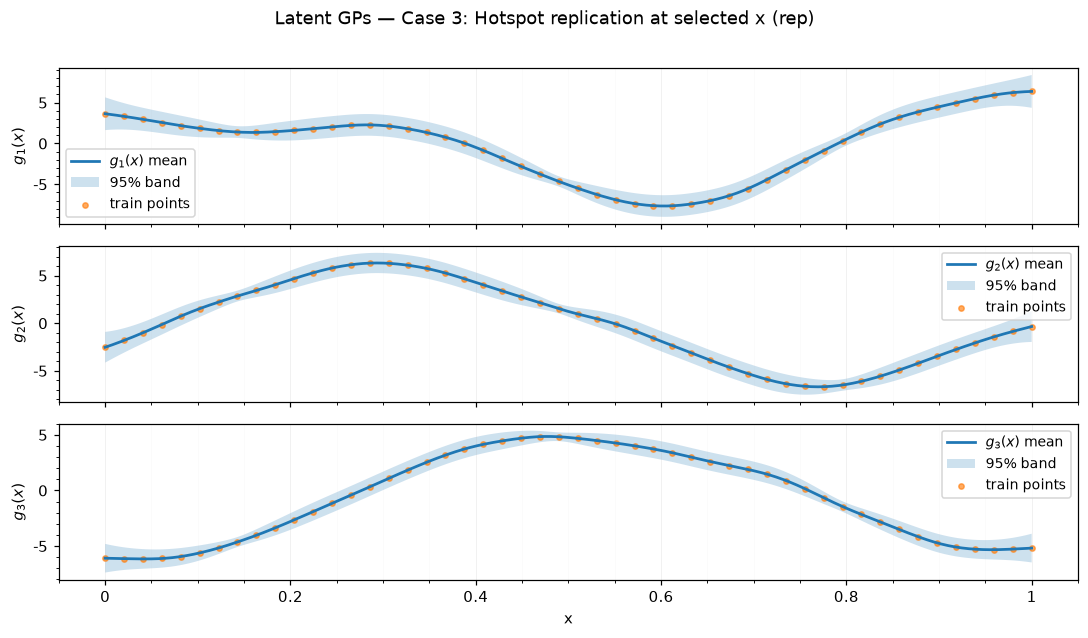
Saved figures to results_figure_jupyterbook/case_3_rep/.
Case 3: Hotspot replication at selected x — full
| case | case label | submethod | N total | unique x | rep min | rep mean | rep max | seed |
|---|---|---|---|---|---|---|---|---|
| 3 | Hotspot replication at selected x | full | 100 | 50 | 1 | 2 | 23 | 343 |
======= VARIANCE OF G ======
tf.Tensor([0.99379099 0.91915887 0.99517028], shape=(3,), dtype=float64)
| case | case label | submethod | training time (s) | RMSE | NRMSE | 95% PI coverage | 95% PI width | DSS |
|---|---|---|---|---|---|---|---|---|
| 3 | Hotspot replication at selected x | full | 4.18 | 0.02 | 0.04 | 1 | 0.16 | -18.56 |
| case | case label | submethod | lengthscales | noise std fitted |
|---|---|---|---|---|
| 3 | Hotspot replication at selected x | full | [[0.14], [0.27], [0.16]] | [0.33, 0.25, 0.65] |
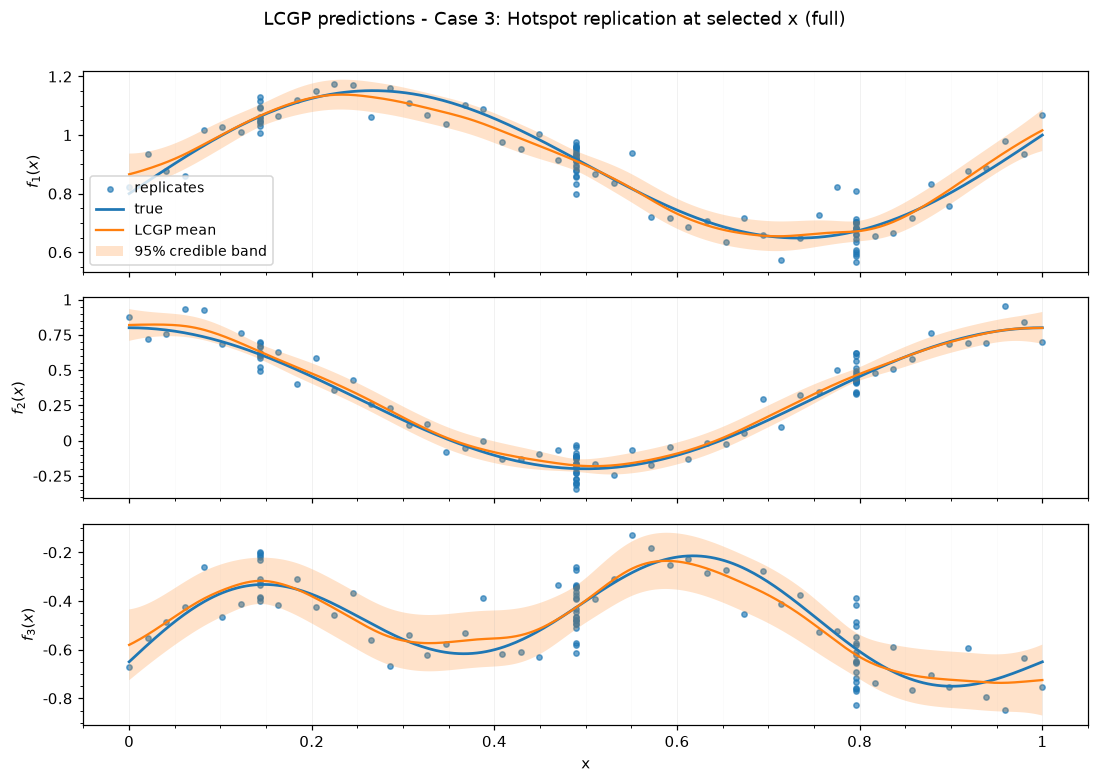
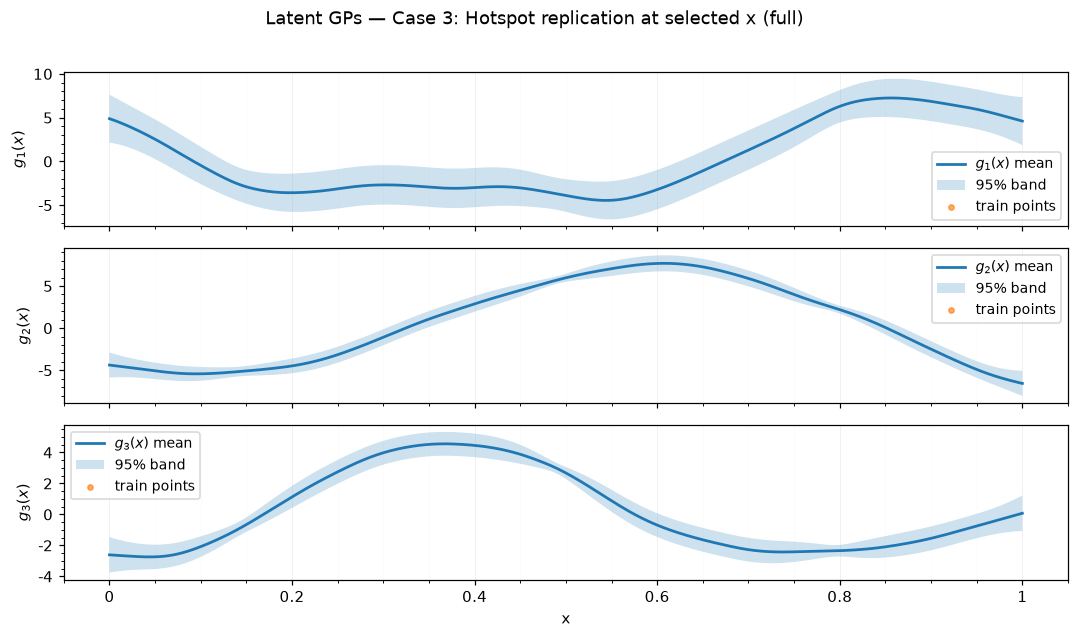
Saved figures to results_figure_jupyterbook/case_3_full/.
Summary tables#
replication_summary = pd.DataFrame(summary_rows)
metric_summary = pd.DataFrame(metric_rows)
diagnostic_summary = pd.DataFrame(diagnostic_rows)
display(Markdown("### Replication design summary"))
display_table(replication_summary)
display(Markdown("### Predictive performance summary"))
display_table(metric_summary.sort_values(["case", "submethod"]))
display(Markdown("### Fitted diagnostic summary"))
display_table(diagnostic_summary)
Replication design summary
| case | case label | submethod | N total | unique x | rep min | rep mean | rep max | seed |
|---|---|---|---|---|---|---|---|---|
| 1 | Uniform replication | rep | 41 | 16 | 1 | 2.56 | 5 | 142 |
| 1 | Uniform replication | full | 51 | 16 | 1 | 3.19 | 5 | 143 |
| 2 | Uneven replication | rep | 199 | 40 | 1 | 4.97 | 20 | 242 |
| 2 | Uneven replication | full | 198 | 40 | 1 | 4.95 | 20 | 243 |
| 3 | Hotspot replication at selected x | rep | 96 | 50 | 1 | 1.92 | 21 | 342 |
| 3 | Hotspot replication at selected x | full | 100 | 50 | 1 | 2 | 23 | 343 |
Predictive performance summary
| case | case label | submethod | training time (s) | RMSE | NRMSE | 95% PI coverage | 95% PI width | DSS |
|---|---|---|---|---|---|---|---|---|
| 1 | Uniform replication | full | 3.01 | 0.03 | 0.06 | 0.97 | 0.18 | -16.95 |
| 1 | Uniform replication | rep | 5.19 | 0.04 | 0.07 | 1 | 0.23 | -15.61 |
| 2 | Uneven replication | full | 9.46 | 0.02 | 0.04 | 1 | 0.15 | -18.87 |
| 2 | Uneven replication | rep | 2.67 | 0.03 | 0.05 | 0.96 | 0.09 | -19.76 |
| 3 | Hotspot replication at selected x | full | 4.18 | 0.02 | 0.04 | 1 | 0.16 | -18.56 |
| 3 | Hotspot replication at selected x | rep | 2.19 | 0.03 | 0.05 | 0.97 | 0.12 | -18.99 |
Fitted diagnostic summary
| case | case label | submethod | lengthscales | noise std fitted |
|---|---|---|---|---|
| 1 | Uniform replication | rep | [[0.13], [0.21], [0.09]] | [0, 0.01, 0] |
| 1 | Uniform replication | full | [[0.18], [0.21], [0.18]] | [0.27, 0.22, 0.82] |
| 2 | Uneven replication | rep | [[0.19], [0.28], [0.25]] | [0.04, 0.07, 0.09] |
| 2 | Uneven replication | full | [[0.27], [0.13], [0.38]] | [0.73, 0.31, 0.96] |
| 3 | Hotspot replication at selected x | rep | [[0.18], [0.19], [0.25]] | [0.05, 0.08, 0.11] |
| 3 | Hotspot replication at selected x | full | [[0.14], [0.27], [0.16]] | [0.33, 0.25, 0.65] |